前言
第一次听到RISC-V这个词大概是两年前,当时觉得它也就是和MIPS这些CPU架构没什么区别,因此也就不以为然了。直到去年,RISC-V这个词开始频繁地出现在微信和其他网站上,此时我再也不能无动于衷了,于是开始在网上搜索有关它的资料,开始知道有SiFive这个网站,知道SiFive出了好几款RISC-V的开发板。可是最便宜的那一块开发板都要700多RMB,最后还是忍痛出手了一块。由于平时上班比较忙,所以玩这块板子的时间并不多,也就是晚上下班后和周末玩玩,自己照着芯片手册写了几个例程在板子上跑跑而已。
再后来发现网上已经有如何设计RISC-V处理器的书籍卖了,并且这个处理器是开源的,于是果断买了一本来阅读并浏览了它的开源代码,最后表示看不懂。从那之后一个“从零开始写RISC-V处理器”的想法开始不断地出现在我的脑海里。我心里是很想学习、深入研究RISC-V的,但是一直以来都没有verilog和FPGA的基础,可以说是CPU设计领域里的门外汉,再加上很少业余时间,为此一度犹豫不决。但是直觉告诉我已近不能再等了,我决定开始自学verilog和FPGA,用简单易懂的方式写一个RISC-V处理器并且把它开源出来,在提高自身的同时希望能帮助到那些想入门RISC-V的同学,于是tinyriscv终于在2019年12月诞生了。
tinyriscv是一个采用三级流水线设计,顺序、单发射、单核的32位RISC-V处理器,全部代码都是采用verilog HDL语言编写,核心设计思想是简单、易懂。
绪论
RISC-V是什么
RISC,即精简指令集处理器,是相对于X86这种CISC(复杂指令集处理器)来说的。RISC-V中的V是罗马数字,也即阿拉伯数字中的5,就是指第5代RISC。
RISC-V是一种指令集架构,和ARM、MIPS这些是属于同一类东西。RISC-V诞生于2010年,最大的特点是开源,任何人都可以设计RISC-V架构的处理器并且不会有任何版权问题。
既生ARM,何生RISC-V
ARM是一种很优秀的处理器,这一点是无可否认的,在RISC处理器中是处于绝对老大的地位。但是ARM是闭源的,要设计基于ARM的处理器是要交版权费的,或者说要购买ARM的授权,而且这授权费用是昂贵的。
RISC-V的诞生并不是偶然的,而是必然的,为什么?且由我从以下两大领域进行说明。
先看开源软件领域(或者说是操作系统领域),Windows是闭源的,Linux是开源的,Linux有多成功、对开源软件有多重要的意义,这个不用多说了吧。再看手机操作系统领域,iOS是闭源的,Android是开源的,Android有多成功,这个也不用多说了吧。对于RISC处理器领域,由于有了ARM的闭源,必然就会有另外一种开源的RISC处理器。RISC-V之于CPU的意义,就好比Linux之于开源软件的意义。
或者你会说现在也有好多开源的处理器架构啊,比如MIPS等等,为什么偏偏是RISC-V?这个在这里我就不细说了,我只想说一句:大部分人能看到的机遇不会是一个好的机遇,你懂的。
可以说未来十年乃至更长时间内不会有比RISC-V更优秀的开源处理器架构出现。错过RISC-V,你注定要错过一个时代。
浅谈Verilog
verilog,确切来说应该是verilog HDL(Hardware Description Language ),从它的名字就可以知道这是一种硬件描述语言。首先它是一种语言,和C语言、C++语言一样是一种编程语言,那么verilog描述的是什么硬件呢?描述电阻?描述电容?描述运算放大器?都不是,它描述的是数字电路里的硬件,比如与、非门、触发器、锁存器等等。
既然是编程语言,那一定会有它的语法,学过C语言的同学再来看verilog得代码,会发现有很多地方是相似的。
verilog的语法并不难,难的是什么时候该用wire类型,什么时候该用reg类型,什么时候该用assign来描述电路,什么时候该用always来描述电路。assign能描述组合逻辑电路,always也能描述组合逻辑电路,两者有什么区别呢?
用always描述组合逻辑电路
我们知道数字电路里有两大类型的电路,一种是组合逻辑电路,另外一种是时序逻辑电路。组合逻辑电路不需要时钟作为触发条件,因此输入会立即(不考虑延时)反映到输出。时序逻辑电路以时钟作为触发条件,时钟的上升沿到来时输入才会反映到输出。
在verilog中,assign能描述组合逻辑电路,always也能描述组合逻辑电路。对于简单的组合逻辑电路的话两者描述起来都比较好懂、容易理解,但是一旦到了复杂的组合逻辑电路,如果用assign描述的话要么是一大串要么是要用好多个assign,不容易弄明白。但是用always描述起来却是非常容易理解的。
既然这样,那全部组合逻辑电路都用always来描述好了,呵呵,既然assign存在就有它的合理性。
用always描述组合逻辑电路时要注意避免产生锁存器,if和case的分支情况要写全。
在tinyriscv中用了大量的always来描述组合逻辑电路,特别是在译码和执行阶段。
数字电路设计中的时序问题
要分析数字电路中的时序问题,就一定要提到以下这个模型。

其中对时序影响最大的是上图中的组合逻辑电路。所以要避免时序问题,最简单的方法减小组合逻辑电路的延时。组合逻辑电路里的串联级数越多延时就越大,实在没办法减小串联级数时,可以采用流水线的方式将这些级数用触发器隔开。
流水线设计
要设计处理器的话,流水线是绕不开的。当然你也可以抬杠说:”用状态机也可以实现处理器啊,不一定要用流水线。”
采用流水线设计方式,不但可以提高处理器的工作频率,还可以提高处理器的效率。但是流水线并不是越长越好,流水线越长要使用的资源就越多、面积就越大。
在设计一款处理器之前,首先要确定好所设计的处理器要达到什么样的性能(或者说主频最高是多少),所使用的资源的上限是多少,功耗范围是多少。如果一味地追求性能而不考虑资源和功耗的话,那么所设计出来的处理器估计就只能用来玩玩,或者做做学术研究。
tinyriscv采用的是三级流水线,即取指、译码和执行,设计的目标就是要对标ARM的Cortex-M3系列处理器。
代码风格
代码风格其实并没有一种标准,但是并不代表代码风格不重要。好的代码风格可以让别人看你的代码时有一种赏心悦目的感觉。哪怕代码只是写给自己看,也一定要养成好的代码风格的习惯。tinyriscv的代码风格在很大程度上沿用了写C语言代码所采用的风格。
下面介绍tinyriscv的一些主要的代码风格。
缩进
统一使用4个空格。
if语句
不管if语句下面有多少行语句,if下面的语句都由begin…end包起来,并且begin在if的最后,如下所示:
1 | if (a == 1'b1) begin |
case语句
对于每一个分支情况,不管有多少行语句,都由begin…end包起来,如下所示:
1 | case (a) |
always语句
always语句后跟begin,如下所示:
1 | always @ (posedge clk) begin |
其他
=、==、<=、>=、+、-、*、/、@等符号左右各有一个空格。
,和:符号后面有一个空格。
对于模块的输入信号,不省略wire关键字。
每个文件的最后留一行空行。
if、case、always后面都有一个空格。
硬件篇
硬件篇主要介绍tinyriscv的verilog代码设计。
tinyriscv整体框架如图2_1所示。
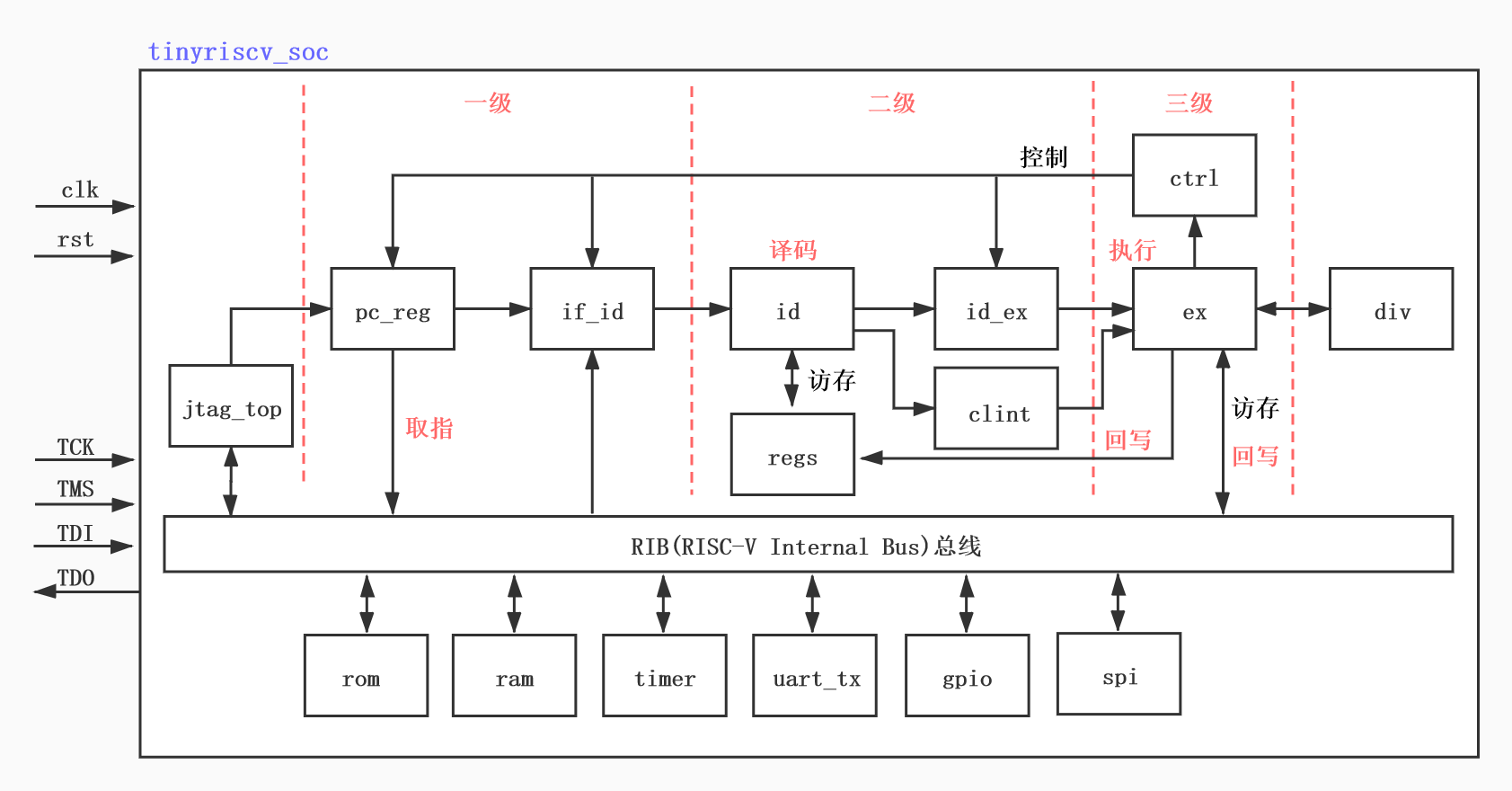
图2_1 tinyriscv整体框架
可见目前tinyriscv已经不仅仅是一个内核了,而是一个小型的SOC,包含一些简单的外设,如timer、uart_tx等。
tinyriscv SOC输入输出信号有两部分,一部分是系统时钟clk和复位信号rst,另一部分是JTAG调试信号,TCK、TMS、TDI和TDO。
上图中的小方框表示一个个模块,方框里面的文字表示模块的名字,箭头则表示模块与模块之间的的输入输出关系。
下面简单介绍每个模块的主要作用。
jtag_top:调试模块的顶层模块,主要有三大类型的信号,第一种是读写内存的信号,第二种是读写寄存器的信号,第三种是控制信号,比如复位MCU,暂停MCU等。
pc_reg:PC寄存器模块,用于产生PC寄存器的值,该值会被用作指令存储器的地址信号。
if_id:取指到译码之间的模块,用于将指令存储器输出的指令打一拍后送到译码模块。
id:译码模块,纯组合逻辑电路,根据if_id模块送进来的指令进行译码。当译码出具体的指令(比如add指令)后,产生是否写寄存器信号,读寄存器信号等。由于寄存器采用的是异步读方式,因此只要送出读寄存器信号后,会马上得到对应的寄存器数据,这个数据会和写寄存器信号一起送到id_ex模块。
id_ex:译码到执行之间的模块,用于将是否写寄存器的信号和寄存器数据打一拍后送到执行模块。
ex:执行模块,纯组合逻辑电路,根据具体的指令进行相应的操作,比如add指令就执行加法操作等。此外,如果是lw等访存指令的话,则会进行读内存操作,读内存也是采用异步读方式。最后将是否需要写寄存器、写寄存器地址,写寄存器数据信号送给regs模块,将是否需要写内存、写内存地址、写内存数据信号送给rib总线,由总线来分配访问的模块。
div:除法模块,采用试商法实现,因此至少需要32个时钟才能完成一次除法操作。
ctrl:控制模块,产生暂停流水线、跳转等控制信号。
clint:核心本地中断模块,对输入的中断请求信号进行总裁,产生最终的中断信号。
rom:程序存储器模块,用于存储程序(bin)文件。
ram:数据存储器模块,用于存储程序中的数据。
timer:定时器模块,用于计时和产生定时中断信号。目前支持RTOS时需要用到该定时器。
uart_tx:串口发送模块,主要用于调试打印。
gpio:简单的IO口模块,主要用于点灯调试。
spi:目前只有master角色,用于访问spi从机,比如spi norflash。
PC寄存器
PC寄存器模块所在的源文件:rtl/core/pc_reg.v
PC寄存器模块的输入输出信号如下表所示:
| 序号 | 信号名 | 输入/输出 | 位宽(bits) | 说明 |
|---|---|---|---|---|
| 1 | clk | 输入 | 1 | 时钟输入信号 |
| 2 | rst | 输入 | 1 | 复位输入信号 |
| 3 | jump_flag_i | 输入 | 1 | 跳转标志 |
| 4 | jump_addr_i | 输入 | 32 | 跳转地址,即跳转到该地址 |
| 5 | hold_flag_i | 输入 | 3 | 暂停标志,即PC寄存器的值保持不变 |
| 6 | jtag_reset_flag_i | 输入 | 1 | 复位标志,即设置为复位后的值 |
| 7 | pc_o | 输出 | 32 | PC寄存器值,即从该值处取指 |
PC寄存器模块代码比较简单,直接贴出来:
1 | always @ (posedge clk) begin |
第3行,PC寄存器的值恢复到原始值(复位后的值)有两种方式,第一种不用说了,就是复位信号有效。第二种是收到jtag模块发过来的复位信号。PC寄存器复位后的值为CpuResetAddr,即32’h0,可以通过改变CpuResetAddr的值来改变PC寄存器的复位值。
第6行,判断跳转标志是否有效,如果有效则直接将PC寄存器的值设置为jump_addr_i的值。因此可以知道,所谓的跳转就是改变PC寄存器的值,从而使CPU从该跳转地址开始取指。
第9行,判断暂停标志是否大于等于Hold_Pc,该值为3’b001。如果是,则保持PC寄存器的值不变。这里可能会有疑问,为什么Hold_Pc的值不是一个1bit的信号。因为这个暂停标志还会被if_id和id_ex模块使用,如果仅仅需要暂停PC寄存器的话,那么if_id模块和id_ex模块是不需要暂停的。当需要暂停if_id模块时,PC寄存器也会同时被暂停。当需要暂停id_ex模块时,那么整条流水线都会被暂停。
第13行,将PC寄存器的值加4。在这里可以知道,tinyriscv的取指地址是4字节对齐的,每条指令都是32位的。
通用寄存器
通用寄存器模块所在的源文件:rtl/core/regs.v
一共有32个通用寄存器x0~x31,其中寄存器x0是只读寄存器并且其值固定为0。
通用寄存器的输入输出信号如下表所示:
| 序号 | 信号名 | 输入/输出 | 位宽(bits) | 说明 |
|---|---|---|---|---|
| 1 | clk | 输入 | 1 | 时钟输入 |
| 2 | rst | 输入 | 1 | 复位输入 |
| 3 | we_i | 输入 | 1 | 来自执行模块的写使能 |
| 4 | waddr_i | 输入 | 5 | 来自执行模块的写地址 |
| 5 | wdata_i | 输入 | 32 | 来自执行模块的写数据 |
| 6 | jtag_we_i | 输入 | 1 | 来自jtag模块的写使能 |
| 7 | jtag_addr_i | 输入 | 5 | 来自jtag模块的写地址 |
| 8 | jtag_data_i | 输入 | 32 | 来自jtag模块的写数据 |
| 9 | raddr1_i | 输入 | 5 | 来自译码模块的寄存器1读地址 |
| 10 | rdata1_o | 输出 | 32 | 寄存器1读数据 |
| 11 | raddr2_i | 输入 | 5 | 来自译码模块的寄存器2读地址 |
| 12 | rdata2_o | 输出 | 32 | 寄存器2读数据 |
| 13 | jtag_data_o | 输出 | 32 | jtag读数据 |
注意,这里的寄存器1不是指x1寄存器,寄存器2也不是指x2寄存器。而是指一条指令里涉及到的两个寄存器(源寄存器1和源寄存器2)。一条指令可能会同时读取两个寄存器的值,所以有两个读端口。又因为jtag模块也会进行寄存器的读操作,所以一共有三个读端口。
读寄存器操作来自译码模块,并且读出来的寄存器数据也会返回给译码模块。写寄存器操作来自执行模块。
先看读操作的代码,如下:
1 | // 读寄存器1 |
可以看到两个寄存器的读操作几乎是一样的。因此在这里只解析读寄存器1那部分代码。
第5行,如果是读寄存器0(x0),那么直接返回0就可以了。
第8行,这涉及到数据相关问题。由于流水线的原因,当前指令处于执行阶段的时候,下一条指令则处于译码阶段。由于执行阶段不会写寄存器,而是在下一个时钟到来时才会进行寄存器写操作,如果译码阶段的指令需要上一条指令的结果,那么此时读到的寄存器的值是错误的。比如下面这两条指令:
1 | add x1, x2, x3 |
第二条指令依赖于第一条指令的结果。为了解决这个数据相关的问题就有了第8~9行的操作,即如果读寄存器等于写寄存器,则直接将要写的值返回给读操作。
第11行,如果没有数据相关,则返回要读的寄存器的值。
下面看写寄存器操作,代码如下:
1 | // 写寄存器 |
第5~6行,如果执行模块写使能并且要写的寄存器不是x0寄存器,则将要写的值写到对应的寄存器。
第7~8行,jtag模块的写操作。
CSR寄存器模块(csr_reg.v)和通用寄存器模块的读、写操作是类似的,这里就不重复了。
取指
目前tinyriscv所有外设(包括rom和ram)、寄存器的读取都是与时钟无关的,或者说所有外设、寄存器的读取采用的是组合逻辑的方式。这一点非常重要!
tinyriscv并没有具体的取指模块和代码。PC寄存器模块的输出pc_o会连接到外设rom模块的地址输入,又由于rom的读取是组合逻辑,因此每一个时钟上升沿到来之前(时序是满足要求的),从rom输出的指令已经稳定在if_id模块的输入,当时钟上升沿到来时指令就会输出到id模块。
取到的指令和指令地址会输入到if_id模块(if_id.v),if_id模块是一个时序电路,作用是将输入的信号打一拍后再输出到译码(id.v)模块。
译码
译码模块所在的源文件:rtl/core/id.v
译码(id)模块是一个纯组合逻辑电路,主要作用有以下几点:
1.根据指令内容,解析出当前具体是哪一条指令(比如add指令)。
2.根据具体的指令,确定当前指令涉及的寄存器。比如读寄存器是一个还是两个,是否需要写寄存器以及写哪一个寄存器。
3.访问通用寄存器,得到要读的寄存器的值。
译码模块的输入输出信号如下表所示:
| 序号 | 信号名 | 输入/输出 | 位宽(bits) | 说明 |
|---|---|---|---|---|
| 1 | rst | 输入 | 1 | 复位信号 |
| 2 | inst_i | 输入 | 32 | 指令内容 |
| 3 | inst_addr_i | 输入 | 32 | 指令地址 |
| 4 | reg1_rdata_i | 输入 | 32 | 寄存器1输入数据 |
| 5 | reg2_rdata_i | 输入 | 32 | 寄存器2输入数据 |
| 6 | csr_rdata_i | 输入 | 32 | CSR寄存器输入数据 |
| 7 | ex_jump_flag_i | 输入 | 1 | 跳转信号 |
| 8 | reg1_raddr_o | 输出 | 5 | 读寄存器1地址,即读哪一个通用寄存器 |
| 9 | reg2_raddr_o | 输出 | 5 | 读寄存器2地址,即读哪一个通用寄存器 |
| 10 | csr_raddr_o | 输出 | 32 | 读csr寄存器地址,即读哪一个CSR寄存器 |
| 11 | mem_req_o | 输出 | 1 | 向总线请求访问内存信号 |
| 12 | inst_o | 输出 | 32 | 指令内容 |
| 13 | inst_addr_o | 输出 | 32 | 指令地址 |
| 14 | reg1_rdata_o | 输出 | 32 | 通用寄存器1数据 |
| 15 | reg2_rdata_o | 输出 | 32 | 通用寄存器2数据 |
| 16 | reg_we_o | 输出 | 1 | 通用寄存器写使能 |
| 17 | reg_waddr_o | 输出 | 5 | 通用寄存器写地址,即写哪一个通用寄存器 |
| 18 | csr_we_o | 输出 | 1 | CSR寄存器写使能 |
| 19 | csr_rdata_o | 输出 | 32 | CSR寄存器读数据 |
| 20 | csr_waddr_o | 输出 | 32 | CSR寄存器写地址,即写哪一个CSR寄存器 |
以add指令为例来说明如何译码。下图是add指令的编码格式:

可知,add指令被编码成6部分内容。通过第1、4、6这三部分可以唯一确定当前指令是否是add指令。知道是add指令之后,就可以知道add指令需要读两个通用寄存器(rs1和rs2)和写一个通用寄存器(rd)。下面看具体的代码:
1 | case (opcode) |
第1行,opcode就是指令编码中的第6部分内容。
第3行,`INST_TYPE_R_M的值为7’b0110011。
第4行,funct7是指指令编码中的第1部分内容。
第5行,funct3是指指令编码中的第4部分内容。
第6行,到了这里,第1、4、6这三部分已经译码完毕,已经可以确定当前指令是add指令了。
第7行,设置写寄存器标志为1,表示执行模块结束后的下一个时钟需要写寄存器。
第8行,设置写寄存器地址为rd,rd的值为指令编码里的第5部分内容。
第9行,设置读寄存器1的地址为rs1,rs1的值为指令编码里的第3部分内容。
第10行,设置读寄存器2的地址为rs2,rs2的值为指令编码里的第2部分内容。
其他指令的译码过程是类似的,这里就不重复了。译码模块看起来代码很多,但是大部分代码都是类似的。
译码模块还有个作用是当指令为加载内存指令(比如lw等)时,向总线发出请求访问内存的信号。这部分内容将在总线一节再分析。
译码模块的输出会送到id_ex模块(id_ex.v)的输入,id_ex模块是一个时序电路,作用是将输入的信号打一拍后再输出到执行模块(ex.v)。
执行
执行模块所在的源文件:rtl/core/ex.v
执行(ex)模块是一个纯组合逻辑电路,主要作用有以下几点:
1.根据当前是什么指令执行对应的操作,比如add指令,则将寄存器1的值和寄存器2的值相加。
2.如果是内存加载指令,则读取对应地址的内存数据。
3.如果是跳转指令,则发出跳转信号。
执行模块的输入输出信号如下表所示:
| 序号 | 信号名 | 输入/输出 | 位宽(bits) | 说明 |
|---|---|---|---|---|
| 1 | rst | 输入 | 1 | 复位信号 |
| 2 | inst_i | 输入 | 32 | 指令内容 |
| 3 | inst_addr_i | 输入 | 32 | 指令地址 |
| 4 | reg_we_i | 输入 | 1 | 寄存器写使能 |
| 5 | reg_waddr_i | 输入 | 5 | 通用寄存器写地址,即写哪一个通用寄存器 |
| 6 | reg1_rdata_i | 输入 | 32 | 通用寄存器1读数据 |
| 7 | reg2_rdata_i | 输入 | 32 | 通用寄存器2读数据 |
| 8 | csr_we_i | 输入 | 1 | CSR寄存器写使能 |
| 9 | csr_waddr_i | 输入 | 32 | CSR寄存器写地址,即写哪一个CSR寄存器 |
| 10 | csr_rdata_i | 输入 | 32 | CSR寄存器读数据 |
| 11 | int_assert_i | 输入 | 1 | 中断信号 |
| 12 | int_addr_i | 输入 | 32 | 中断跳转地址,即中断发生后跳转到哪个地址 |
| 13 | mem_rdata_i | 输入 | 32 | 内存读数据 |
| 14 | div_ready_i | 输入 | 1 | 除法模块是否准备好信号,即是否可以进行除法运算 |
| 15 | div_result_i | 输入 | 64 | 除法结果 |
| 16 | div_busy_i | 输入 | 1 | 除法模块忙信号,即正在进行除法运算 |
| 17 | div_op_i | 输入 | 3 | 具体的除法运算,即DIV、DIVU、REM和REMU中的哪一种 |
| 18 | div_reg_waddr_i | 输入 | 5 | 除法运算完成后要写的通用寄存器地址 |
| 19 | mem_wdata_o | 输出 | 32 | 内存写数据 |
| 20 | mem_raddr_o | 输出 | 32 | 内存读地址 |
| 21 | mem_waddr_o | 输出 | 32 | 内存写地址 |
| 22 | mem_we_o | 输出 | 1 | 内存写使能 |
| 23 | mem_req_o | 输出 | 1 | 请求访问内存信号 |
| 24 | reg_wdata_o | 输出 | 32 | 通用寄存器写数据 |
| 25 | reg_we_o | 输出 | 1 | 通用寄存器写使能 |
| 26 | reg_waddr_o | 输出 | 5 | 通用寄存器写地址 |
| 27 | csr_wdata_o | 输出 | 32 | CSR寄存器写数据 |
| 28 | csr_we_o | 输出 | 1 | CSR寄存器写使能 |
| 29 | csr_waddr_o | 输出 | 32 | CSR寄存器写地址,即写哪一个CSR寄存器 |
| 30 | div_start_o | 输出 | 1 | 开始除法运算 |
| 31 | div_dividend_o | 输出 | 32 | 除法运算中的被除数 |
| 32 | div_divisor_o | 输出 | 32 | 除法运算中的除数 |
| 33 | div_op_o | 输出 | 3 | 具体的除法运算,即DIV、DIVU、REM和REMU中的哪一种 |
| 34 | div_reg_waddr_o | 输出 | 5 | 除法运算完成后要写的通用寄存器地址 |
| 35 | hold_flag_o | 输出 | 1 | 暂停流水线信号 |
| 36 | jump_flag_o | 输出 | 1 | 跳转信号 |
| 37 | jump_addr_o | 输出 | 32 | 跳转地址 |
下面以add指令为例说明,add指令的作用就是将寄存器1的值和寄存器2的值相加,最后将结果写入目的寄存器。代码如下:
1 | ... |
第2~4行,译码操作。
第5行,对add或sub指令进行处理。
第6~12行,当前指令不涉及到的操作(比如跳转、写内存等)需要将其置回默认值。
第13行,指令编码中的第30位区分是add指令还是sub指令。0表示add指令,1表示sub指令。
第14行,执行加法操作。
第16行,执行减法操作。
其他指令的执行是类似的,需要注意的是没有涉及的信号要将其置为默认值,if和case情况要写全,避免产生锁存器。
下面以beq指令说明跳转指令的执行。beq指令的编码如下:

beq指令的作用就是当寄存器1的值和寄存器2的值相等时发生跳转,跳转的目的地址为当前指令的地址加上符号扩展的imm的值。具体代码如下:
1 | ... |
第2~4行,译码出beq指令。
第5~10行,没有涉及的信号置为默认值。
第11行,判断寄存器1的值是否等于寄存器2的值。
第12行,跳转使能,即发生跳转。
第13行,计算出跳转的目的地址。
第15、16行,不发生跳转。
其他跳转指令的执行是类似的,这里就不再重复了。
访存
由于tinyriscv只有三级流水线,因此没有访存这个阶段,访存的操作放在了执行模块中。具体是这样的,在译码阶段如果识别出是内存访问指令(lb、lh、lw、lbu、lhu、sb、sh、sw),则向总线发出内存访问请求,具体代码(位于id.v)如下:
1 | ... |
第2~4行,译码出内存加载指令,lb、lh、lw、lbu、lhu。
第5行,需要读寄存器1。
第6行,不需要读寄存器2。
第7行,写目的寄存器使能。
第8行,写目的寄存器的地址,即写哪一个通用寄存器。
第9行,发出访问内存请求。
第19~21行,译码出内存存储指令,sb、sw、sh。
第22行,需要读寄存器1。
第23行,需要读寄存器2。
第24行,不需要写目的寄存器。
第26行,发出访问内存请求。
问题来了,为什么在取指阶段发出内存访问请求?这跟总线的设计是相关的,这里先不具体介绍总线的设计,只需要知道如果需要访问内存,则需要提前一个时钟向总线发出请求。
在译码阶段向总线发出内存访问请求后,在执行阶段就会得到对应的内存数据。
下面看执行阶段的内存加载操作,以lb指令为例,lb指令的作用是访问内存中的某一个字节,代码(位于ex.v)如下:
1 | ... |
第2~4行,译码出lb指令。
第5~10行,将没有涉及的信号置为默认值。
第11行,得到访存的地址。
第12行,由于访问内存的地址必须是4字节对齐的,因此这里的mem_raddr_index的含义就是32位内存数据(4个字节)中的哪一个字节,2’b00表示第0个字节,即最低字节,2’b01表示第1个字节,2’b10表示第2个字节,2’b11表示第3个字节,即最高字节。
第14、17、20、23行,写寄存器数据。
回写
由于tinyriscv只有三级流水线,因此也没有回写(write back,或者说写回)这个阶段,在执行阶段结束后的下一个时钟上升沿就会把数据写回寄存器或者内存。
需要注意的是,在执行阶段,判断如果是内存存储指令(sb、sh、sw),则向总线发出访问内存请求。而对于内存加载(lb、lh、lw、lbu、lhu)指令是不需要的。因为内存存储指令既需要加载内存数据又需要往内存存储数据。
以sb指令为例,代码(位于ex.v)如下:
1 | ... |
第2~4行,译码出sb指令。
第5~8行,将没有涉及的信号置为默认值。
第9行,写内存使能。
第10行,发出访问内存请求。
第11行,内存写地址。
第12行,内存读地址,读地址和写地址是一样的。
第13行,mem_waddr_index的含义就是写32位内存数据中的哪一个字节。
第15、18、21、24行,写内存数据。
sb指令只改变读出来的32位内存数据中对应的字节,其他3个字节的数据保持不变,然后写回到内存中。
跳转和流水线暂停
跳转就是改变PC寄存器的值。又因为跳转与否需要在执行阶段才知道,所以当需要跳转时,则需要暂停流水线(正确来说是冲刷流水线。流水线是不可以暂停的,除非时钟不跑了)。那怎么暂停流水线呢?或者说怎么实现流水线冲刷呢?tinyriscv的流水线结构如下图所示。
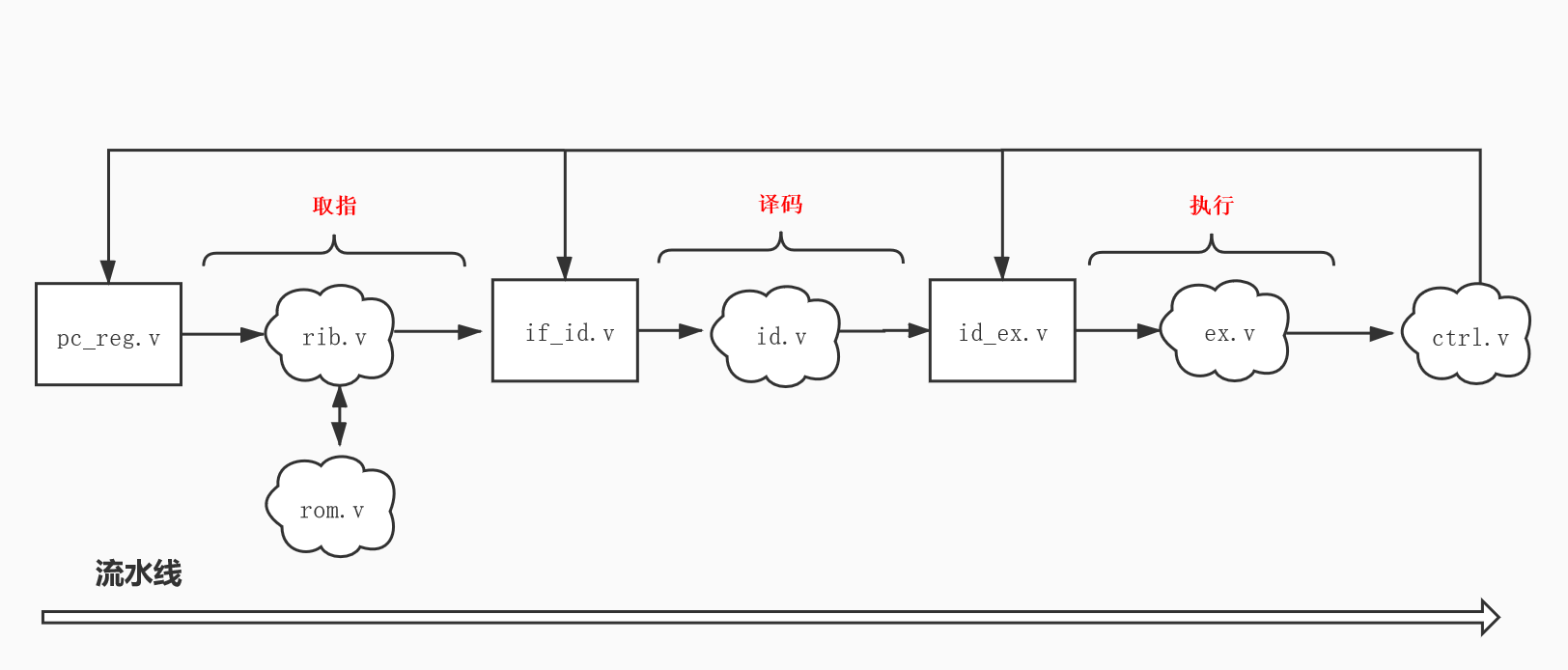
其中长方形表示的是时序逻辑电路,云状型表示的是组合逻辑电路。在执行阶段,当判断需要发生跳转时,发出跳转信号和跳转地址给ctrl(ctrl.v)模块。ctrl模块判断跳转信号有效后会给pc_reg、if_id和id_ex模块发出流水线暂停信号,并且还会给pc_reg模块发出跳转地址。在时钟上升沿到来时,if_id和id_ex模块如果检测到流水线暂停信号有效则送出NOP指令,从而使得整条流水线(译码阶段、执行阶段)流淌的都是NOP指令,已经取出的指令就会无效,这就是流水线冲刷机制。
下面看ctrl.v模块是怎么设计的。ctrl.v的输入输出信号如下表所示:
| 序号 | 信号名 | 输入/输出 | 位宽(bits) | 说明 |
|---|---|---|---|---|
| 1 | rst | 输入 | 1 | 复位信号 |
| 2 | jump_flag_i | 输入 | 1 | 跳转标志 |
| 3 | jump_addr_i | 输入 | 32 | 跳转地址 |
| 4 | hold_flag_ex_i | 输入 | 1 | 来自执行模块的暂停标志 |
| 5 | hold_flag_rib_i | 输入 | 1 | 来自总线模块的暂停标志 |
| 6 | jtag_halt_flag_i | 输入 | 1 | 来自jtag模块的暂停标志 |
| 7 | hold_flag_clint_i | 输入 | 1 | 来自中断模块的暂停标志 |
| 8 | hold_flag_o | 输出 | 3 | 暂停标志 |
| 9 | jump_flag_o | 输出 | 1 | 跳转标志 |
| 10 | jump_addr_o | 输出 | 32 | 跳转地址 |
可知,暂停信号来自多个模块。对于跳转(跳转包含暂停流水线操作),是要冲刷整条流水线的,因为跳转后流水线上其他阶段的其他操作是无效的。对于其他模块的暂停信号,一种最简单的设计就是也冲刷整条流水线,但是这样的话MCU的效率就会低一些。另一种设计就是根据不同的暂停信号,暂停不同的流水线阶段。比如对于总线请求的暂停只需要暂停PC寄存器这一阶段就可以了,让流水线上的其他阶段继续工作。看ctrl.v的代码:
1 | ... |
第3~6行,复位时赋默认值。
第8行,输出跳转地址直接等于输入跳转地址。
第9行,输出跳转标志直接等于输入跳转标志。
第11行,默认不暂停流水线。
第13、14行,对于跳转操作、来自执行阶段的暂停、来自中断模块的暂停则暂停整条流水线。
第16~18行,对于总线暂停,只需要暂停PC寄存器,让译码和执行阶段继续运行。
第19~21行,对于jtag模块暂停,则暂停整条流水线。
跳转时只需要暂停流水线一个时钟周期,但是如果是多周期指令(比如除法指令),则需要暂停流水线多个时钟周期。
总线
设想一下一个没有总线的SOC,处理器核与外设之间的连接是怎样的。可能会如下图所示:
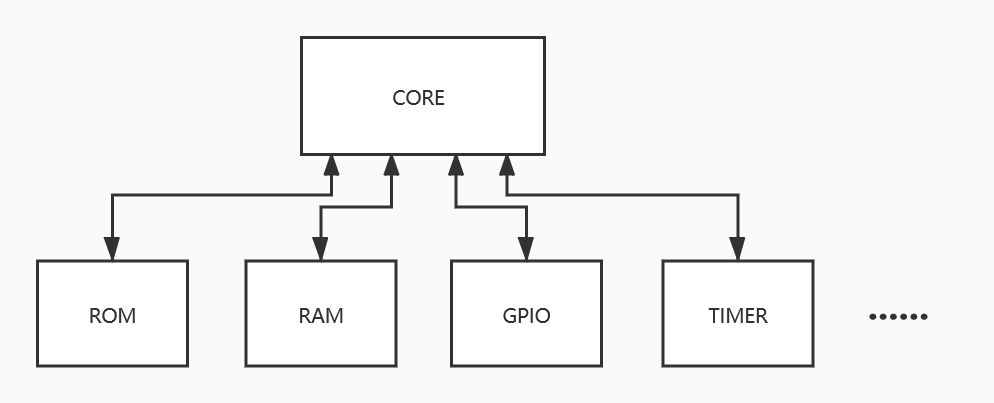
可见,处理器核core直接与每个外设进行交互。假设一个外设有一条地址总线和一条数据总线,总共有N个外设,那么处理器核就有N条地址总线和N条数据总线,而且每增加一个外设就要修改(改动还不小)core的代码。有了总线之后(见本章开头的图2_1),处理器核只需要一条地址总线和一条数据总线,大大简化了处理器核与外设之间的连接。
目前已经有不少成熟、标准的总线,比如AMBA、wishbone、AXI等。设计CPU时大可以直接使用其中某一种,以节省开发时间。但是为了追求简单,tinyriscv并没有使用这些总线,而是自主设计了一种名为RIB(RISC-V Internal Bus)的总线。RIB总线支持多主多从连接,但是同一时刻只支持一主一从通信。RIB总线上的各个主设备之间采用固定优先级仲裁机制。
RIB总线模块所在的源文件:rtl/core/rib.v
RIB总线模块的输入输出信号如下表所示(由于各个主、从之间的信号是类似的,所以这里只列出其中一个主和一个从的信号):
| 序号 | 信号名 | 输入/输出 | 位宽(bits) | 说明 |
|---|---|---|---|---|
| 1 | m0_addr_i | 输入 | 32 | 主设备0读写外设地址 |
| 2 | m0_data_i | 输入 | 32 | 主设备0写外设数据 |
| 3 | m0_data_o | 输出 | 32 | 主设备0读取到的数据 |
| 4 | m0_ack_o | 输出 | 1 | 主设备0访问完成标志 |
| 5 | m0_req_i | 输入 | 1 | 主设备0访问请求标志 |
| 6 | m0_we_i | 输入 | 1 | 主设备0写标志 |
| 7 | s0_addr_o | 输出 | 32 | 从设备0读、写地址 |
| 8 | s0_data_o | 输出 | 32 | 从设备0写数据 |
| 9 | s0_data_i | 输入 | 32 | 从设备0读取到的数据 |
| 10 | s0_ack_i | 输入 | 1 | 从设备0访问完成标志 |
| 11 | s0_req_o | 输出 | 1 | 从设备0访问请求标志 |
| 12 | s0_we_o | 输出 | 1 | 从设备0写标志 |
RIB总线本质上是一个多路选择器,从多个主设备中选择其中一个来访问对应的从设备。
RIB总线地址的最高4位决定要访问的是哪一个从设备,因此最多支持16个从设备。
仲裁方式采用的类似状态机的方式来实现,代码如下所示:
1 | ... |
第3行,主设备请求信号的组合。
第7~13行,切换主设备操作,默认是授权给主设备1的,即取指模块。从这里可以知道,从发出总线访问请求后,需要一个时钟周期才能完成切换。
第18~66行,通过组合逻辑电路来实现优先级仲裁。
第20行,默认授权给主设备1。
第24~35行,这是已经授权给主设备0的情况。第25、28、31行,分别对应主设备0、主设备2和主设备1的请求,通过if、else语句来实现优先级。第27、30行,主设备0和主设备2的请求需要暂停流水线,这里只需要暂停PC阶段,让译码和执行阶段继续执行。
第3647行,这是已经授权给主设备1的情况,和第2435行的操作是类似的。
第4859行,这是已经授权给主设备2的情况,和第2435行的操作是类似的。
注意:RIB总线上不同的主设备切换是需要一个时钟周期的,因此如果想要在执行阶段读取到外设的数据,则需要在译码阶段就发出总线访问请求。
中断
中断(中断返回)本质上也是一种跳转,只不过还需要附加一些读写CSR寄存器的操作。
RISC-V中断分为两种类型,一种是同步中断,即ECALL、EBREAK等指令所产生的中断,另一种是异步中断,即GPIO、UART等外设产生的中断。
对于中断模块设计,一种简单的方法就是当检测到中断(中断返回)信号时,先暂停整条流水线,设置跳转地址为中断入口地址,然后读、写必要的CSR寄存器(mstatus、mepc、mcause等),等读写完这些CSR寄存器后取消流水线暂停,这样处理器就可以从中断入口地址开始取指,进入中断服务程序。
下面看tinyriscv的中断是如何设计的。中断模块所在文件:rtl/core/clint.v
输入输出信号列表如下:
| 序号 | 信号名 | 输入/输出 | 位宽(bits) | 说明 |
|---|---|---|---|---|
| 1 | clk | 输入 | 1 | 时钟信号 |
| 2 | rst | 输入 | 1 | 复位信号 |
| 3 | int_flag_i | 输入 | 8 | 外设中断信号 |
| 4 | inst_i | 输入 | 32 | 指令内容 |
| 5 | inst_addr_i | 输入 | 32 | 指令地址 |
| 6 | hold_flag_i | 输入 | 1 | 未使用 |
| 7 | data_i | 输入 | 32 | 未使用 |
| 8 | csr_mtvec | 输入 | 32 | mtvec寄存器内容 |
| 9 | csr_mepc | 输入 | 32 | mepc寄存器内容 |
| 10 | csr_mstatus | 输入 | 32 | mstatus寄存器内容 |
| 11 | global_int_en_i | 输入 | 1 | 全局外设中断使能 |
| 12 | hold_flag_o | 输出 | 1 | 流水线暂停标志 |
| 13 | we_o | 输出 | 1 | 写使能 |
| 14 | waddr_o | 输出 | 32 | 写地址 |
| 15 | raddr_o | 输出 | 32 | 读地址 |
| 16 | data_o | 输出 | 32 | 写数据 |
| 17 | int_addr_o | 输出 | 32 | 中断入口地址 |
| 18 | int_assert_o | 输出 | 1 | 中断有效标志 |
先看中断模块是怎样判断有中断信号产生的,如下代码:
1 | ... |
第3~4行,复位后的状态,默认没有中断要处理。
第6~7行,判断当前指令是否是ECALL或者EBREAK指令,如果是则设置中断状态为S_INT_SYNC_ASSERT,表示有同步中断要处理。
第8~9行,判断是否有外设中断信号产生,如果是则设置中断状态为S_INT_ASYNC_ASSERT,表示有异步中断要处理。
第10~11行,判断当前指令是否是MRET指令,MRET指令是中断返回指令。如果是,则设置中断状态为S_INT_MRET。
下面就根据当前的中断状态做不同处理(读写不同的CSR寄存器),代码如下:
1 | ... |
第3~6行,CSR状态默认处于S_CSR_IDLE。
第1023行,当CSR处于S_CSR_IDLE时,如果中断状态为S_INT_SYNC_ASSERT,则在第11行将CSR状态设置为S_CSR_MEPC,在第12行将当前指令地址保存下来。在第1323行,根据不同的指令类型,设置不同的中断码(Exception Code),这样在中断服务程序里就可以知道当前中断发生的原因了。
第24~28行,目前tinyriscv只支持定时器这个外设中断。
第30~31行,如果是中断返回指令,则设置CSR状态为S_CSR_MSTATUS_MRET。
第34~48行,一个时钟切换一下CSR状态。
接下来就是写CSR寄存器操作,需要根据上面的CSR状态来写。
1 | ... |
第11~15行,写mepc寄存器。
第17~21行,写mcause寄存器。
第23~27行,关闭全局异步中断。
第29~33行,写mstatus寄存器。
最后就是发出中断信号,中断信号会进入到执行阶段。
1 | ... |
有两种情况需要发出中断信号,一种是进入中断,另一种是退出中断。
第9~12行,写完mstatus寄存器后发出中断进入信号,中断入口地址就是mtvec寄存器的值。
第13~15行,发出中断退出信号,中断退出地址就是mepc寄存器的值。
JTAG
JTAG作为一种调试接口,在处理器设计里算是比较大而且复杂、却不起眼的一个模块,绝大部分开源处理器核都没有JTAG(调试)模块。但是为了完整性,tinyriscv还是加入了JTAG模块,还单独为JTAG写了一篇文章《深入浅出RISC-V调试》,感兴趣的同学可以去看一下,这里不再单独介绍了。要明白JTAG模块的设计原理,必须先看懂RISC-V的debug spec。
RTL仿真验证
写完处理器代码后,怎么证明所写的处理器是能正确执行指令的呢?这时就需要写testbench来测试了。其实在写代码的时候就应该在头脑里进行仿真。这里并没有使用ModelSim这些软件进行仿真,而是使用了一个轻量级的iverilog和vvp工具。
在写testbench文件时,有两点需要注意的,第一点就是在testbench文件里加上读指令文件的操作:
1 | initial begin |
第2行代码的作用就是将inst.data文件读入到rom模块里,inst.data里面的内容就是一条条指令,这样处理器开始执行时就可以从rom里取到指令。
第二点就是,在仿真期间将仿真波形dump出到某一个文件里:
1 | initial begin |
这样仿真波形就会被dump出到tinyriscv_soc_tb.vcd文件,使用gtkwave工具就可以查看波形了。
到这里,硬件篇的内容就结束了。
说实话,对于数字设计而言,我只是一名初学者,甚至连门都还没入,有写得不好或者不清楚的地方还请多多包涵。
软件篇
RISC-V汇编语言
汇编语言属于低级语言,这里的低级是相对于C、C++等高级语言而言的,并不是说汇编语言很“low”。汇编语言与具体的CPU架构(ARM、X86、RISC-V等)紧密关联,每一种CPU架构都有其对应的汇编语言。
汇编语言作为连接底层软件和处理器硬件(数字逻辑)的桥梁,要求做硬件和做底层软件的人都必须掌握的,只是要求掌握的程度不一样而已。有不少同学在数字方面很强,甚至整个处理器都写出来了,但是却不知道怎么写汇编语言或者C语言程序在上面跑。
虽然我对RISC-V汇编语言不是很熟悉,但我个人觉得RISC-V汇编语言还是很好掌握的(容易理解)。
RV32I有32个通用寄存器(x0至x31),PC寄存器不在这32个寄存器里面,其中x0为只读寄存器,其值固定为0。在RISC-V汇编语言程序里,我们一般看到的不是x0、x1、x2等这些名字,而是zero、ra、sp等名字,是因为这里的x0至x31有其对应的ABI(application
binary interface)名字,如下表所示:
| 寄存器 | ABI | 寄存器 | ABI | 寄存器 | ABI |
|---|---|---|---|---|---|
| x0 | zero | x11 | a1 | x22 | s6 |
| x1 | ra | x12 | a2 | x23 | s7 |
| x2 | sp | x13 | a3 | x24 | s8 |
| x3 | gp | x14 | a4 | x25 | s9 |
| x4 | tp | x15 | a5 | x26 | s10 |
| x5 | t0 | x16 | a6 | x27 | s11 |
| x6 | t1 | x17 | a7 | x28 | t3 |
| x7 | t2 | x18 | s2 | x29 | t4 |
| x8 | s0或者fp | x19 | s3 | x30 | t5 |
| x9 | s1 | x20 | s4 | x31 | t6 |
| x10 | a0 | x21 | s5 |
在汇编程序里,寄存器名字和ABI名字是可以直接互换的。
下面是一些汇编指令,注意这些指令不是RISC-V特有的,而是GCC编译器都有的指令。
.align:2的N次方个字节对齐,比如.align 3,表示8字节对齐。
.globl:声明全局符号,比如.globl mytest,声明一个mytest的全局符号,这样在其他文件里就可以引用该符号。
.equ:常量定义,比如.equ MAX 10。
.macro:宏定义。
.endm:宏定义结束,与.macro配套使用。
.section:段定义,比如.section .text.start,定义.text.start段。
下面是一些常用的RISC-V整数指令。
1.lui指令
语法:lui rd, imm,作用是将imm的低12位置0,结果写入rd寄存器。
2.auipc指令
语法:auipc rd, imm,作用是将imm的高20位左移12位,低12位置0,然后加上PC的值,结果写入rd寄存器。
3.jal指令
语法:jal rd, offset或者jal offset,作用是将PC的值加上4,结果写入rd寄存器,rd默认为x1,同时将PC的值加上offset。
4.jalr指令
语法:jalr rd, rs1或者jalr rs1,作用是将PC的值加上4,结果写入rd寄存器,rd默认为x1,同时将PC的值加上符号位扩展之后的rs1的值。
5.beq指令
语法:beq rs1, rs2, offset,作用是如果rs1的值等于rs2的值,则将PC设置为符号位扩展后的offset的值。
6.bne指令
语法:bne rs1, rs2, offset,作用是如果rs1的值不等于rs2的值,则将PC设置为符号位扩展后的offset的值。
7.blt指令
语法:blt rs1, rs2, offset,作用是如果rs1的值小于rs2的值(rs1和rs2均视为有符号数),则将PC设置为符号位扩展后的offset的值。
8.bge指令
语法:bge rs1, rs2, offset,作用是如果rs1的值大于等于rs2的值(rs1和rs2均视为有符号数),则将PC设置为符号位扩展后的offset的值。
9.bltu指令
语法:bltu rs1, rs2, offset,作用是如果rs1的值小于rs2的值(rs1和rs2均视为无符号数),则将PC设置为符号位扩展后的offset的值。
10.bgeu指令
语法:bgeu rs1, rs2, offset,作用是如果rs1的值大于等于rs2的值(rs1和rs2均视为无符号数),则将PC设置为符号位扩展后的offset的值。
11.lb指令
语法:lb rd, offset(rs1),作用是从rs1加上offset的地址处读取一个字节的内容,并将该内容经符号位扩展后写入rd寄存器。
12.lh指令
语法:lh rd, offset(rs1),作用是从rs1加上offset的地址处读取两个字节的内容,并将该内容经符号位扩展后写入rd寄存器。
13.lw指令
语法:lw rd, offset(rs1),作用是从rs1加上offset的地址处读取四个字节的内容,结果写入rd寄存器。
14.lbu指令
语法:lbu rd, offset(rs1),作用是从rs1加上offset的地址处读取一个字节的内容,并将该内容经0扩展后写入rd寄存器。
15.lhu指令
语法:lhu rd, offset(rs1),作用是从rs1加上offset的地址处读取两个字节的内容,并将该内容经0扩展后写入rd寄存器。
16.sb指令
语法:sb rs2, offset(rs1),作用是将rs2的最低一个字节写入rs1加上offset的地址处。
17.sh指令
语法:sh rs2, offset(rs1),作用是将rs2的最低两个字节写入rs1加上offset的地址处。
18.sw指令
语法:sw rs2, offset(rs1),作用是将rs2的值写入rs1加上offset的地址处。
19.addi指令
语法:addi rd, rs1, imm,作用是将符号扩展的立即数imm的值加上rs1的值,结果写入rd寄存器,忽略算术溢出。
20.slti指令
语法:slti rd, rs1, imm,作用是将符号扩展的立即数imm的值与rs1的值比较(有符号数比较),如果rs1的值更小,则向rd寄存器写1,否则写0。
21.sltiu指令
语法:sltiu rd, rs1, imm,作用是将符号扩展的立即数imm的值与rs1的值比较(无符号数比较),如果rs1的值更小,则向rd寄存器写1,否则写0。
22.xori指令
语法:xori rd, rs1, imm,作用是将rs1与符号位扩展的imm按位异或,结果写入rd寄存器。
23.ori指令
语法:ori rd, rs1, imm,作用是将rs1与符号位扩展的imm按位或,结果写入rd寄存器。
24.andi指令
语法:andi rd, rs1, imm,作用是将rs1与符号位扩展的imm按位与,结果写入rd寄存器。
25.slli指令
语法:slli rd, rs1, shamt,作用是将rs1左移shamt位,空出的位补0,结果写入rd寄存器。
26.srli指令
语法:srli rd, rs1, shamt,作用是将rs1右移shamt位,空出的位补0,结果写入rd寄存器。
27.srai指令
语法:srai rd, rs1, shamt,作用是将rs1右移shamt位,空出的位用rs1的最高位补充,结果写入rd寄存器。
28.add指令
语法:add rd, rs1, rs2,作用是将rs1寄存器的值加上rs2寄存器的值,然后将结果写入rd寄存器里,忽略算术溢出。
29.sub指令
语法:sub rd, rs1, rs2,作用是将rs1寄存器的值减去rs2寄存器的值,然后将结果写入rd寄存器里,忽略算术溢出。
30.sll指令
语法:sll rd, rs1, rs2,作用是将rs1左移rs2位(低5位有效),空出的位补0,结果写入rd寄存器。
31.slt指令
语法:slt rd, rs1, rs2,作用是将rs1的值与rs2的值比较(有符号数比较),如果rs1的值更小,则向rd寄存器写1,否则写0。
32.sltu指令
语法:sltu rd, rs1, rs2,作用是将rs1的值与rs2的值比较(无符号数比较),如果rs1的值更小,则向rd寄存器写1,否则写0。
33.xor指令
语法:xor rd, rs1, rs2,作用是将rs1与rs2按位异或,结果写入rd寄存器。
34.srl指令
语法:srl rd, rs1, rs2,作用是将rs1右移rs2位(低5位有效),空出的位补0,结果写入rd寄存器。
35.sra指令
语法:sra rd, rs1, rs2,作用是将rs1右移rs2位(低5位有效),空出的位用rs1的最高位补充,结果写入rd寄存器。
36.or指令
语法:or rd, rs1, rs2,作用是将rs1与rs2按位或,结果写入rd寄存器。
37.and指令
语法:and rd, rs1, rs2,作用是将rs1与rs2按位与,结果写入rd寄存器。
38.ecall指令
语法:ecall,作用是进入异常处理程序,常用于OS的系统调用(上下文切换)。
39.ebreak
语法:ebreak,作用是进入调试模式。
以下是CSR指令。
1.csrrw指令
语法:csrrw rd, csr, rs1,作用是将csr寄存器的值读入rd,然后将rs1的值写入csr寄存器。
2.csrrs指令
语法:csrrs rd, csr, rs1,作用是将csr寄存器的值读入rd,然后将rs1的值与csr的值按位或后的结果写入csr寄存器。
3.csrrc指令
语法:csrrc rd, csr, rs1,作用是将csr寄存器的值读入rd,然后将rs1的值与csr的值按位与后的结果写入csr寄存器。
4.csrrwi指令
语法:csrrwi rd, csr, imm,作用是将csr寄存器的值读入rd,然后将0扩展后的imm的值写入csr寄存器。
5.csrrsi指令
语法:csrrsi rd, csr, imm,作用是将csr寄存器的值读入rd,然后将0扩展后的imm的值与csr的值按位或后的结果写入csr寄存器。
6.csrrci指令
语法:csrrci rd, csr, imm,作用是将csr寄存器的值读入rd,然后将0扩展后的imm的值与csr的值按位与后的结果写入csr寄存器。
我们都知道,学习一门程序语言时如果单单学习语法的话会觉得很枯燥,所以下面就以tinyriscv的启动文件start.S里的汇编程序来实战分析一下。完整的代码如下:
1 | .section .init; |
第1行,定义.init段。
第2行,声明全局符号_start。
第3行,_start是一个函数。
第5行,_start标签,用来指示start的地址。
第8行,la是伪指令,对应到RISC-V汇编里是auipc和lw这两条指令,这里的作用是将__global_pointer标签的地址读入gp寄存器。
第10行,将_sp的地址读入sp寄存器,sp寄存器的值在这里初始化。
第12行,li是伪指令,对应到RISC-V汇编里是lui和addi这两条指令(或者只有lui这一条指令),这里是将x26寄存器的值清零。
第13行,将x27寄存器的值清零。
第17行,加载_data_lma的地址(数据段的数据在flash的起始地址)到a0寄存器。
第18行,加载_data的地址(数据段的数据在ram的起始地址)到a1寄存器。
第19行,加载_edata的地址(数据段的结束地址)到a2寄存器。
第20行,比较a1和a2的大小,如果a1大于等于a2,则跳转到第27行,否则往下执行。
第22行,从a0地址处读4个字节到t0寄存器。
第23行,将t0寄存器的值存入a1地址处。第22行、第23行的作用就是将一个word的数据从flash里搬到ram。
第24行,a0的值加4,指向下一个word。
第25行,a1的值加4,指向下一个word。
第26行,比较a1和a2的大小,如果a1小于a2,则跳转到21行,否则往下执行。到这里就可以知道,第22行~第26行代码的作用就是将存在flash里的全部数据搬到ram里。
第30行,将__bss_start的地址(bss段的起始地址)读到a0寄存器。
第31行,将_end的地址(bss段的结束地址)读到a1寄存器。
第32行,比较a0和a1的大小,如果a0大于等于a1,则跳转到第37行,否则往下执行。
第34行,将a0地址处的内容清零。
第35行,a0的值加4,指向下一个地址。
第36行,比较a0和a1的大小,如果a0小于a1,则跳转到第33行,否则往下执行。到这里就知道,第33行~第36行的作用就是将bss段的内容全部清零。
第39行,call是伪指令,语法:call rd, symbol。在这里会转换成在RISC-V汇编里的auipc和jalr这两条指令,作用是将PC+8的值保存到rd寄存器(默认为x1寄存器),然后将PC设置为symbol的值,这样就实现了跳转并保存返回地址。这里是调用_init函数。
第40行,调用main函数,这里就进入到C语言里的main函数了。
第43行,设置x26寄存器的值为1,表示仿真结束。
第46~47行,死循环,原地跳转。
在这里要说明一下,上面启动代码里的从flash搬数据到ram和清零bss段这两块代码是嵌入式启动代码里非常常见的,也是比较通用的,必须要理解并掌握。
Makefile
用过make命令来编译程序的应该都知道Makefile。Makefile文件里包含一系列目标构建规则,当我们在终端里输入make命令然后回车时make工具就会在当前目录下查找Makefile(或者makefile)文件,然后根据Makefile文件里的规则来构建目标。可以说,学习Makefile就是学习这些构建规则。
Make可以管理工程的编译步骤,这样就不需要每次都输入一大串命令来编译程序了,编写好Makefile后,只需要输入make命令即可自动完成整个工程的编译、构建。可以这么说,是否掌握Makefile,从侧面反映出你是否具有管理代码工程的能力。
关于Makefile的详细介绍网上已有不少,因此这里只作简单介绍。
1.Makefile文件规则
Makefile文件由一系列规则组成,每条规则如下:
1 | <target>:<prerequisites> |
第一行里的target叫做目标,prerequisites叫做依赖。
第二行以tab键缩进,后面跟着一条或多条命令,这里的命令是shell命令。
简单来说就是,make需要生成对应的目标时,先查找其依赖是否都已经存在,如果都已经存在则执行命令,如果不存在则先去查找生成依赖的规则,如此不断地查找下去,直到所有依赖都生成完毕。
1.1目标
在一条规则里,目标是必须要有的,依赖和命令可有可无。
当输入make命令不带任何参数时,make首先查找Makefile里的第一个目标,当然也可以指定目标,比如:
make test
来指定执行构建test目标。
如果当前目录下刚好存在一个test文件,这时make不会构建Makefile文件里的test目标,这时就需要使用.PHONY来指定test为伪目标,例如:
1 | .PHONY: test |
1.2依赖
依赖可以是一个或者多个文件,又或者是一个或多个目标。如果依赖不存在或者依赖的时间戳比目标的时间戳新(依赖被更新过),则会重新构建目标。
1.3命令
命令通常是用来表示如何生成(更新)目标的,由一个或者多个shell命令组成。每行命令前必须有一个tab键(不是空格)。
2.Makefile语法
2.1注释
Makefile中的注释和shell脚本中的注释一样,使用#符号表示注释的开始,注意Makeifle中只有单行注释,好比C语言中的//,如果需要多行注释则需要使用多个#号。
2.2变量和赋值
Makefile中可以使用=、?=、:=、+=这4种符号对变量进行赋值,这四种赋值的区别为:
1 | = 表示在执行时再进行赋值 |
对变量进行引用时使用$(变量)形式,比如:
1 | VAR = 123 |
2.3内置变量
make工具提供了一些内置变量,比如CC表示当前使用的编译器,MAKE表示当前使用的make工具,这些都是为了跨平台使用的。
2.4自动变量
make工具提供了一些自动变量,这些变量的值与当前的规则有关,即不同的规则这些变量的值可能就会不一样。
1 | $@:表示完整的目标名字,包括后缀 |
2.5内置函数
make工具提供了很多内置函数可以直接调用,这里列举以下一些函数。
2.5.1wildcard函数
扩展通配符函数,用法如下:
cfiles := $(wildcard *.c)
作用是匹配当前目录(不包含子目录)下所有.c文件,每个文件以空格隔开,然后赋值给cfiles变量。
2.5.2patsubst函数
替换通配符函数,结合wildcard函数用法如下:
objs := $(patsubst %.c,%.o,$(wildcard *.c))
作用是将当前目录(不包含子目录)下所有的.c文件替换成对应的.o文件,即将后缀为.c的文件替换为后缀为.o的文件,每个文件以空格隔开,然后赋值给objs变量。
2.5.3abspath函数
文件绝对路径函数,用法如下:
path := $(abspath main.c)
作用是获取当前目录下main.c文件的绝对路径(含文件名,结果比如:/work/main.c),然后赋值给path变量。
Makefile的内容就介绍到这里,下面以tinyriscv项目里的tests/example/simple例程来具体分析。
tests/example/simple/Makefile文件内容如下:
1 | RISCV_ARCH := rv32im |
可以看到都是一些变量赋值操作,需要注意的是第7行,这里的作用是定义SIMULATION这一个宏,对应C语言里的代码为:
#define SIMULATION
第18行,包含common.mk文件,类似于C语言里的#include操作。
下面看一下common.mk文件:
1 |
|
第2~12行,作用是定义交叉工具链的路径,如果你的工具链路径跟这里的不一致,那就需要修改这几行。
第14~15行,定义all目标,为默认(第一个)目标。
第17~23行,把公共的C语言文件和汇编文件添加进来。
第25行,指定链接脚本。
第27行,指定头文件路径。
第29行,指定链接参数。
第31行,将ASM_SRCS变量里所有的.S文件替换成对应的.o文件。
第32行,将C_SRCS变量里所有的.c文件替换成对应的.o文件。
第39行,指定-march参数的值,这里为rv32im,即tinyriscv处理器支持的指令类型为整形(必须支持)和乘除(M扩展)。
第40行,指定-mabi参数的值,这里为ilp32,即整型、长整型、指针都为32位。
第43~46行,all目标的生成规则。
第44行,编译生成目标的elf文件,即生成simple文件。
第45行,根据elf文件生成bin文件,即生成simple.bin文件。
第46行,将elf文件反汇编,即生成simple.dump文件。
第48~49行,这个规则的作用是根据ASM_OBJS变量里的.o文件找到对应的.S文件,然后将该.S文件使用第49行的命令进行编译。
第5152行,与第4849行类似,这个规则的作用是根据C_OBJS变量里的.o文件找到对应的.c文件,然后将该.c文件使用第52行的命令进行编译。
第54~56行,定义clean目标,当在命令行输入make clean时就会执行这条规则,作用是删除所有的.o文件。
common.mk是公共文件,所有的例程都会用到它。
链接脚本
我们所编写的代码最终要能被处理器执行,一般需要经过编译、汇编和链接这3个过程。其中链接这个过程是链接器(比如riscv32-unknown-elf-ld程序)做的,链接器在链接过程中需要一个文件来告诉自己需要将输入的代码、数据等内容如何输出到可执行文件(比如elf文件)中。这个文件就是链接脚本(linker script),链接脚本定义了内存布局和控制输入内容如何映射到输出文件。链接脚本文件一般以ld或者lds作为后缀。
链接脚本与具体的处理器息息相关,每一家公司、个人开发的处理器所用到的链接脚本都有可能是不一样的。幸运的是,对于具体的处理器架构(ARM、RISC-V等),它们的链接脚本是大同小异的。如果你要设计一款处理器,那么链接脚本是必须要掌握的一门知识。
链接脚本可以说是比较冷门的技术了,除了官方文档外几乎找不到更好的参考资料,因此要掌握好这门技术,这里建议是多多阅读不同处理器的链接脚本,多看看别人的链接脚本是怎么写的。掌握链接脚本可以让你对程序地址空间、加载和启动有更深的理解。
这里并不会介绍链接脚本的全部内容,只会针对tinyriscv处理器的链接脚本涉及到的内容进行说明。
链接脚本里有两个比较重要关键字,分别是MEMORY和SECTIONS。其中MEMORY用于描述内存(比如ROM、RAM、Flash等)布局,包括每一块内存的起始地址、大小和属性。SECTIONS用于描述输入段(input section)如何映射到输出段(output section)等。
下面先看MEMORY的语法:
1 | MEMORY |
name是内存块的名字,比如rom、ram、flash等名字。
attr是该块内存的属性,有r(读)、w(写)、x(执行)等属性。
origin是该块内存的起始地址,比如0x10000000。ORIGIN可以缩写成org。
len是该块内存的大小,比如128K、1M等。LENGTH可以缩写成l。
比如tinyriscv链接脚本的MEMORY是这样的:
1 | MEMORY |
下面看SECTIONS的语法:
1 | SECTIONS |
很简单,关键是里面的sections−command的语法:
1 | section [address] [(type)] : |
section:输出段名字,常见的有.text、.data、.bss等。
address:输出段的虚拟内存地址(virtual memory address,VMA),即运行地址。
AT(lma):输出段的加载内存地址(load memory address,LMA),即存储地址。
ALIGN:输出段对齐,以字节为单位。
>region:指定VMA地址。
AT>:指定LMA地址。
这里说一下什么是VMA地址和LMA地址。通常情况下VMA地址等于LMA地址,有玩过ARM或者说STM32的应该知道,通过调试器是可以将程序下载到STM32的RAM里直接跑的,而不需要下载到Flash,这种在RAM里直接跑的程序在链接过程时VMA就等于LMA。这种直接在RAM里运行方式一般只适用于前期程序调试,当掉电后程序就会消失。当程序调试完毕后,此时就需要将程序固化到Flash里,这种需要固化到Flash里的程序在链接过程中就会有些数据(比如全局初始化不为零的data)的VMA地址不等于LMA地址,在程序启动的时候需要将这部分数据从Flash搬到RAM里。
接下来结合实际的链接脚本来分析。看看tinyriscv链接脚本里的SECTIONS是怎样的,这里只列出一部分代码:
1 | SECTIONS |
第3行,定义__stack_size变量,并将其赋值为8K。
第5行,定义.init输出段。
第7行,.init段里包含.init输入段。*号是通配符,KEEP的作用是告诉链接器保留这些输入段,不要优化掉。.init段在start.S文件中定义,从这里可以知道,启动代码放在了flash里的0x00000000地址处。这也知道tinyriscv的程序是从0x0地址开始运行的。
第8行,这里的flash就是前面在MEMORY里定义的内存块,这里指定VMA地址在flash里,LMA地址也是flash里。
第10~16行,应该比较好理解了,定义.text输出段,里面主要放的是代码,同样VMA和LMA地址也是在flash里。
第18行,.符号在链接脚本里加做位置计数器,这个位置计数器只能向后移动,不能向前移动。这行代码的作用就是将位置计数器进行4字节对齐。
第20~22行,PROVIDE的作用是导出全局符号,这里分别导出了3个符号,这些符号的值就等于当前位置计数器的值,这些符号可以被汇编、C语言代码引用。
比如在链接脚本里PROVIDE了3个符号,分别是start_of_ROM、end_of_ROM、start_of_FLASH,在汇编程序里可以这样引用:
1 | la a0, start_of_ROM |
在C语言程序里可以这样引用:
1 | extern char start_of_ROM, end_of_ROM, start_of_FLASH; |
或者这样引用:
1 | extern char start_of_ROM[], end_of_ROM[], start_of_FLASH[]; |
第24~41行,定义.data段,这里的data段的LMA地址不等于VMA地址,VMA地址在ram里,LMA地址在flash里。
第43~51行,定义.bss段,bss段包含一些在程序里全局定义但没有初始化的变量。LMA地址等于VMA地址,都在ram里。
启动代码
启动代码在RISC-V汇编语言那一节已经分析过了,这里就不再重复了。
异常和中断
在RISC-V里,异常(exception)和中断(interrupt)统称为陷阱(trap),这里的异常又可以称作同步中断,而中断是指异步中断。说到异常和中断,就不得不提RISC-V的特权级别(Privilege Levels)了,RISC-V架构目前一共定义了3种特权级别,由低到高分别是用户、监督者和机器级别(模式)。其中机器模式是必须要实现的,监督者和用户模式根据不同的软件系统需求来实现。一般来说,如果是简单的嵌入式系统,则只需要实现机器模式,如果是安全系统,则需要实现机器和监督者模式,如果是类Unix系统,则这3种模式都要实现。每一种特权级别都有其对应的指令集扩展和CSR寄存器(Control and Status Registers)。由于tinyriscv处理器只实现了机器模式,因此这里只介绍机器模式相关的内容。
先看一些跟中断和异常相关的比较重要的CSR寄存器。注意,机器模式相关的CSR寄存器都是以m字母开头的。
mstatus(Machine Status Register)
mstatus[3]:MIE,全局中断使能位,可读可写,该位决定了整个核的中断(异常)是否使能。该位对一些不可屏蔽的中断(NMI)是无效的,比如一些会引起硬件错误的中断(异常)。
mie(Machine Interrupt Enable Register)
mie[3]:MSIE,软件中断使能位,可读可写。
mie[7]:MTIE,定时器中断使能位,可读可写。
mie[11]:MEIE,外部中断使能位,可读可写。
mip(Machine Interrupt Pending Register)
mip[3]:MSIP,软件中断pending位,只读。
mip[7]:MTIP,定时器中断pending位,只读。
mip[11]:MEIP,外部中断pending位,只读。
mtvec(Machine Trap-Vector Base-Address Register)
mtvec[31:2]:中断入口基地址,可读可写,必须4字节对齐。
mtvec[1:0]:中断向量模式,可读可写,当mtvec[1:0]=00时为直接模式,此时所有的异常和中断入口地址都为mtvec[31:2]的值。当mtvec[1:0]=01时为向量模式,所有异常的入口地址为mtvec[31:2]的值,而所有中断的入口地址为mtvec[31:2] + causex4,其中cause为中断号。tinyriscv实现的是直接模式。
mcause(Machine Cause Register)
mcause[31]:中断位,可读可写,表示当trap发生时,该trap中断还是异常,1表示中断,0表示异常。
mcause[30:0]:中断号,可读可写,表示trap发生时所对应的中断(异常)号。比如定时器中断号为7,外部中断号为11,非法指令异常号为2等等。
在中断入口函数里通过读这个寄存器的值就可以知道当前发生的是哪个中断或异常。
mepc(Machine Exception Program Counter)
该寄存器保存中断(异常)返回时PC指针的值,即MCU处理完中断(异常)后从该寄存器所指的地址处继续执行。
中断(异常)代码分析
下面看一下tinyriscv中断处理相关的代码。
首先是中断初始化相关的,启动代码start.S文件里有这么一行代码:
call _init
意思是调用_init()函数,这个函数在init.c文件里定义:
1 | extern void trap_entry(); |
第7行,通过写mtvec寄存器来设置中断入口函数地址,这里的中断入口函数为trap_entry。
第10行,写mstatus的bit3来使能全局中断。
接下来看中断处理相关的,中断处理函数trap_entry定义在trap_entry.S文件里:
1 | #define REGBYTES 4 |
第11行,将sp往低地址移动32个word,腾出来的栈空间用来保存通用寄存器的值。
第1345行,将x1x31寄存器的值保存到栈里面,即保护现场。
第47行,把mcause的值读到a0寄存器里面。
第48行,把mepc的值读到a1寄存器里面。
第50行,将a0寄存器的值逻辑右移31位,然后将右移后的值存到a2寄存器。
第51行,判断a2的值是否等于0,即判断当前trap是中断还是异常,如果等于0(是异常)则跳转到第56行,否则(是中断)继续往下执行。
第53行,调用interrupt_handler()函数,该函数在trap_handler.c文件里定义:
1 | void interrupt_handler(uint32_t mcause, uint32_t mepc) |
因为目前tinyriscv只有定时器0外设这个中断,所以这里面直接调用timer0_irq_handler()函数。timer0_irq_handler()函数在timer_int这个例程的main.c里定义:
1 | void timer0_irq_handler() |
回到trap_entry.S文件。
第54行,跳转操作,跳转到第61行。
第6296行,从栈里恢复x1x31寄存器的值,也就是进入中断前这些寄存器的值。
第98行,中断返回指令。
目前tinyriscv的中断处理流程就是这样的了,下面再看一下异常处理流程。
前面说到当进入trap_entry()函数时,如果mcause的bit31等于0,则会跳转到第56行。
第57行,调用exception_handler()函数:
1 | void exception_handler(uint32_t mcause, uint32_t mepc) |
第3行,判断当前异常是否是由ebreak或者ecall指令导致的,如果是则什么都不处理,直接返回,否则调用第4行,进入死循环。
第58行,将a1寄存器的值加4。
第59行,将a1寄存器的值写入mepc寄存器,即将中断(异常)返回地址加4,指向下一条指令。
到这里,中断和异常的部分就分析完了。
最后说一下,进入中断(异常)时,硬件会把全局中断使能关了,因此在处理中断(异常)过程中默认是不会响应其他中断的,在中断(异常)返回时硬件才会重新使能全局中断。如果要实现中断嵌套(抢占)功能,则需要在中断处理函数里使能全局中断,并且硬件上要实现中断优先级功能。
实践篇
移植tinyriscv到FPGA
这里只介绍xilinx vivado平台的移植,详见tinyriscv项目的fpga/README.md文件。
编写和运行C语言程序
C语言的例程都在tests/example目录里,其中include、lib为公共目录,所有例程都依赖这两个目录。
当所需编写一个新的例程(程序)时,可以通过以下步骤:
1.拷贝simple这个例程,然后改成自己想要的名字。
2.接着修改Makefile文件:
1 | ... |
修改第2行,这个TARGET就是程序编译后生成的bin文件名字,这里是simple.bin。
修改第4行,CFLAGS是编译选项,这里的simple例程默认作为仿真使用,所以需要定义SIMULATION宏。
修改第6行,将需要编译的汇编文件全部添加到这里。
修改第8行,将涉及的头文件路径全部添加到这里。
修改第10行,将需要编译的c文件全部添加到这里。
3.打开终端,进入到例程的根目录,先输入make clean命令再输入make命令即可编译程序。
由于tinyriscv是支持通过jtag下载程序的,因此在fpga综合、实现时不需要预先读入程序(bin)文件,只需要在下载完bitstream文件后连上jtag和openocd,即可通过openocd的load_image命令下载程序。这样的好处是,当需要更新程序时不需要重新综合、实现,可以节省很多时间。
移植FreeRTOS
freertos是一款轻量级的实时嵌入式操作系统,支持多个平台(X86、ARM、RISC-V等)和多种编译器、编译环境(GCC、KEIL、IAR等),具有可配置、任务管理、信号量、消息队列、内存管理和软件定时器等功能。freertos遵循MIT开源协议。
鉴于freertos的国内外的知名度和代码的精简度,这里选择它作为tinyriscv支持的首个RTOS。
目前freertos已经支持好几款RISC-V开发板(处理器)了,比如SiFive的HiFive1_RevB,NXP的Vega。这样的话,在移植freertos到其他RISC-V处理器或者开发板时就不需要从零开始了,直接在其中一个的基础上修改就可以了。事实上,tinyriscv就是这么做的。
RISC-V的中断(异常)架构与ARM相比,其中有一点是做得非常好的,那就是RISC-V的中断(异常)入口地址是可以通过软件修改的(修改mtvec寄存器的值),而不像ARM那样硬件设计好了就不能变了。这样的好处是,在移植freertos时就可以共用原有(其他例程)的启动代码,只需要在系统初始化时设置mtvec为freertos的中断入口地址就可以了。
下面开始分析freertos的代码,先看初始化过程。
tinyriscv的启动代码前面已经分析过了,这里就直接从main()函数开始看了。先给出主要的函数调用层次关系。
1 | examples/FreeRTOS/Demo/tinyriscv_GCC/main.c(main()-->main_blinky()) |
main()函数的定义:
1 | int main( void ) |
第3行,调用prvSetupHardware()函数,这个函数里只做了一件事情,就是将LED对应的GPIO设置为输出模式。
第7行,条件成立。这个demo实现(移植)的就是简单的LED闪灯功能,只不过是通过两个任务来实现。一个任务作为发送者,另一个任务作为接收者,发送者每隔一段时间向接收者发送一个消息,接收者收到这个消息后,判断是否是想要的消息,如果是则将LED所在的GPIO电平取反。
第9行,调用main_blinky()函数:
1 | void main_blinky( void ) |
这里并不会具体分析freertos代码的实现,只有涉及到移植相关的才会详细说明。
第4行,创建队列,发送任务和接收任务会利用这个队列会来收发数据。
第10行,创建接收任务。
第17行,创建发送任务。
第20行,开始任务调度,vTaskStartScheduler()这个函数代码比较长,这里就不贴代码了。这里面有一个很重要的操作,就是调用xPortStartScheduler()函数:
1 | BaseType_t xPortStartScheduler( void ) |
第9行,调用vPortSetupTimerInterrupt()函数,在这个函数里需要初始化操作系统的systick定时器并启动。
第12行,xPortStartFirstTask()函数是用汇编语言实现的,这个函数跟移植密切相关,这里分析一下:
1 | .func |
第4行,条件成立。
第8~9行,将mtvec的值设置为freertos_risc_v_trap_handler()函数的地址,即中断(异常)入口函数为freertos_risc_v_trap_handler()。
后面的代码会将当前TCB里保存的寄存器值恢复到对应的寄存器,当xPortStartFirstTask()函数返回后就会执行当前(pxCurrentTCB所指的)任务。
到这里,我们就可以知道接下来的重点就是freertos_risc_v_trap_handler()函数,这个函数的代码也是比较长,这里只列出tinyriscv用到的部分:
1 | .func |
第3~34行,保护现场,即将寄存器压栈。
第36行,保存额外的寄存器,这里什么都不做。
第38~39行,将sp的值保存在当前TCB的起始地址处。
第41行,读取mcause的值到a0寄存器。
第42行,读取mepc的值到a1寄存器。
第45行,将a0寄存器的值右移31位,将移位后的值写入a2寄存器。
第46行,判断a2寄存器的值是否等于0,即判断是中断(异步中断)还是异常(同步中断),如果等于0则跳转到第59行。这里假设a2的值不等于0,因此继续往下看。
第47行,将中断返回地址保存在栈顶。
第51行,使用中断栈,即在中断里有专门的栈空间来进行函数调用。
第52行,调用xPortClearTimerIntPending()函数,在这里该函数的作用是清定时器中断pending。目前在freertos这个demo里只有定时器中断,因此就没有判断是否是其他外部中断了。
第53行,调用xTaskIncrementTick()函数,这个函数的返回值决定了是否需要切换到其他任务。如果返回值为0,表示不需要切换,否则需要任务切换。
第54行,判断xTaskIncrementTick()函数的返回值是否等于0,如果是则跳转到第80行,这里假设返回值不等于0。
第55行,调用vTaskSwitchContext()函数,这个函数会切换当前TCB到将要执行的任务上。
第57行,跳转到第80行。
第81~82行,使用当前TCB的sp。
第85~86行,将中断返回地址写入mepc寄存器。
第88行,恢复额外的寄存器,这里什么都没做。
第91~122行,从栈里恢复寄存器的值,这和前面进入中断时的保存现场操作是成对的,即恢复现场。
第124行,中断返回,从mepc的值所指的地址处开始执行代码。
接下来,看回第46行,如果a2寄存器的值为0,则跳转到第第59行。
第60行,将a1的值加4,即将中断返回地址的值加4,后面会用到。
第61行,将a1的值写入sp寄存器。
第64~65行,判断a0的值是否等于11,即mcause的值是否等于11,即是否是ecall指令异常。如果不是则跳转到第70行。
第70~74行是一段死循环代码。
第66~68行,前面已经分析过了。
总结一下,移植freertos需要修改以下几个地方:
1.修改prvSetupHardware()函数,在里面做一些硬件初始化的操作。
2.修改vPortSetupTimerInterrupt()函数,在里面初始化并使能系统滴答定时器。
3.修改freertos_risc_v_trap_handler()函数,根据具体的硬件实现处理好中断返回地址和中断(异常)的判断。
写在最后
调试经验
作为一名还没入门的数字设计新手的我,其实没什么设计、调试经验可谈,这里只是分享一下我在设计tinyriscv处理器过程中用到的调试方法。
设计tinyriscv用到的工具有两个,分别是iverilog和gtkwave,这两个都是跨平台、轻量级的工具。iverilog用来编译verilog代码,gtkwave用来查看波形。
验证一个处理器,首先是能跑通各个指令,RISC-V官方提供了指令兼容性测试程序,这些程序是用汇编语言编写的,当编译这些程序之后,会生成对应的elf、bin文件,还有反汇编(dump)文件。通过vvp工具生成波形(vcd)文件后,再用gtkwave打开波形文件,然后对照着反汇编文件查看要关心的信号。比如在测试add指令时,就需要看ex阶段时reg_we_o信号是否为1,reg_wdata_o和reg_waddr_o信号的值是否正确。就这样,将反汇编文件里的每一条指令都对着信号波形走一遍(流水线的每一个阶段),如果所有反汇编指令的执行过程都符合预期,则表示这条指令测试基本上通过了。注意,这里只是说基本上,并不是说一定没问题,因为即使你把RISC-V的全部指令兼容性测试都通过了,也不能说明你设计的RISC-V处理器就没问题了,后续还要经过更多的测试和验证,比如随机指令测试等等。
设计感言
我是从零开始设计tinyriscv处理器的,虽然已经工作好几年了,但是我工作的内容可以说与数字设计没有任何关系。之所以跨度这么大,第一是在各种“掐脖子”的环境下,我个人非常看好RISC-V的前景,我不想错过这个黄金时代。第二是想结合实际工作拓展一下自己的知识面,将底层软件理解得更深入,技多不压身。第三,当时网上关于RISC-V入门的资料还很少,决定自己写一个RISC-V处理器,并将设计过程分享出来,提高自己的同时希望可以帮助到更多想入门RISC-V的同学。第四是机会总是留给有准备的人的,哪天有机会出来创业或者转型的话,RISC-V必定是我的首选。
前面说到我的工作与数字设计是没有关系的,而且上班时间比较长(差不多996),因此我只能利用业余时间、下班后的时间、周末休息的时间来学习,以至于会感觉到休息比上班还要累,放弃了很多陪伴家人和小孩的时间。为了学习verilog和数字设计,我买了不少于10本相关的书籍,一边学一边看,遇到不懂的知识点再查看相关的章节。
对于tinyriscv,我是以一个实际项目来做的,我给自己制定了一个目标,就是每个月至少做一次大的更新。一边做设计一边还要写文档,以至于有段时间好几个月没更新到文档,不少网友都催更了好几次了,在这里跟大家说声不好意思,让你们久等了。有时候眼看快一个月没有更新项目了,此时心里会非常着急,以至于好几次睡梦中都在想着怎么完成本次功能的设计的事情。说实话,我完全可以没有任何压力地、慢慢地去完成这个项目,完全没必要给自己这么大的压力。但我没有这么做,我要对自己负责,更要对这些学习tinyriscv的同学负责。看到大家一个个的star,就是我更新的最大动力。
tinyriscv是我真正做开源、走向开源的第一个项目,通过这个项目我认识了不少朋友,有国内一流大学硕士毕业刚参加工作的HYF同学,有硕士在读的ZK同学,有出版社的编辑,有创业公司的老总等等。目前tinyriscv的功能还不是很完善,更新速度也变慢了,这是因为我在设计上遇到了瓶颈,还有很多相关的知识需要学习才能继续走下去,才能走得更远,还请大家多多见谅。
最后,文笔有限,这个设计文档写得不是详细,写得也不是很好,如有不对的地方还请多多包涵。